Articles Tagged with

This blog post will attempt to give a high-level overview of how we go about automating typically manual Cyber HUMINT ( “a category of intelligence derived from information collected and provided by human sources.”) collection.
Significant elements of this blog will have to be described in general, non-specific, terms or redacted. Due to the nature of the work that we do, keeping our tradecraft methods, tactics and techniques private is important. The methods employed by us are not only commercially sensitive but over disclosure of specific details may render the methods ineffective.
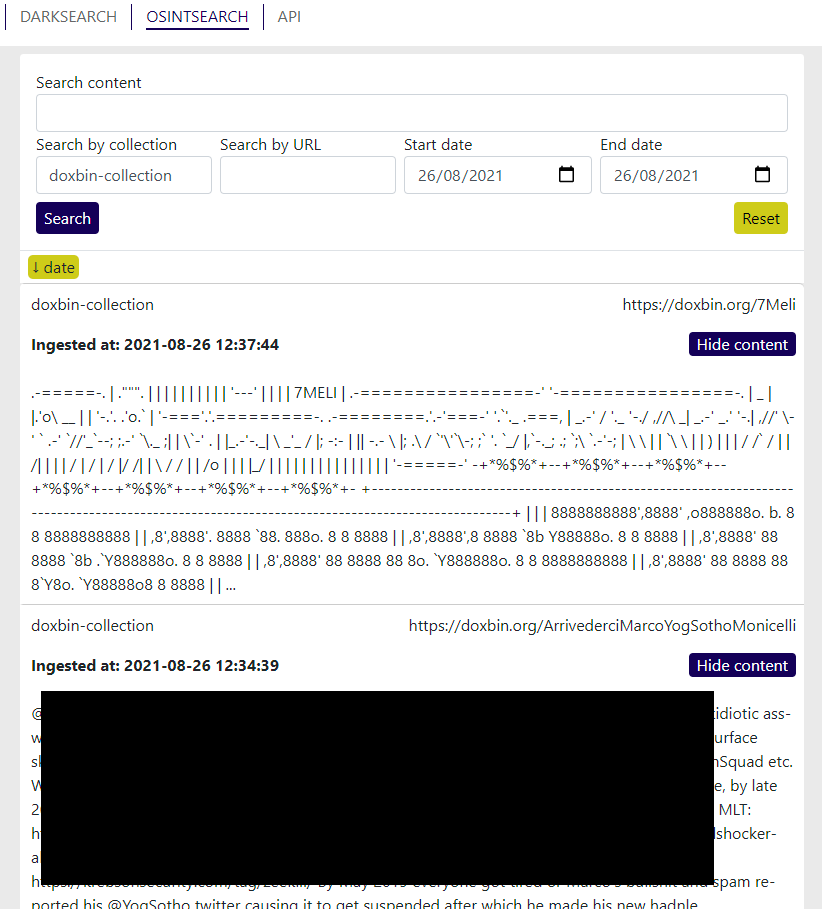
OSINT Source Selection
A fair amount of thought and research goes into selecting our OSINT (Open Source INTelligence) sources. For the most part, ideal collection sources would be ones that offer an API (Application Programming Interface) for information scraping and do so without significant restrictions.
For example, Pastebin with a paid account grants access to a reasonable scraping API. Using this API we’ve been able to create a custom collection to download each paste, analyse it for relevant customer keywords and, if any matches found, store the paste & alert our customers.
In most cases, however, paste sites typically have no available APIs. Where these sites have a rolling list of new pastes posted, and those pastes can be enumerated & are publicly accessible, further development of a custom collection is required.
An automated process is used to periodically check for new and available pastes, fetch those pastes in a raw format where possible, perform keyword matching and store where needed. A significant number of paste sites that we collect from, either on the internet or Dark Web, fall into this category. Generally there are no significant technical challenges other than the creation of a bespoke collection for each specific source type.
As a general rule, for websites that do not have any specifically designed automated collection or scraping method, we apply a high degree of courtesy and do not aggressively scrape the site.
Since the paste enumeration and paste collection is a fairly lightweight process, and given that pastes in general are uploaded every so often, there is no need for any aggressive polling of a target site.
Authenticated Access
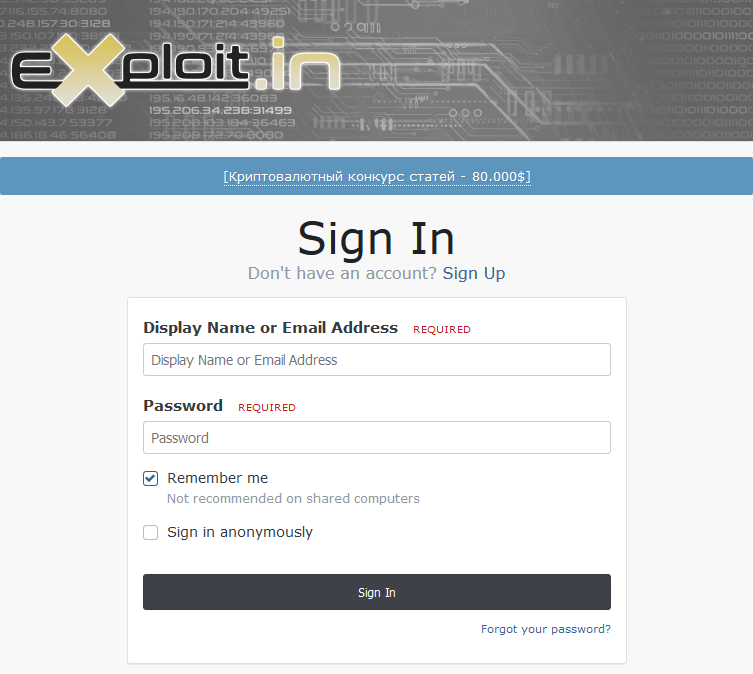
Some of the sources we collect from are closed, member only, Dark Web or internet hacking forums. Without going into too much detail as to how accounts are created on these forums, an account is essential since we must be able to access topics and posts as well as a roll of recent posts.
In most cases forums helpfully provide a feed of new content by way of RSS (Really Simple Syndication) feed. This can in part, like an API, assist in the creation of a custom automated collection for that source. An additional caveat to this being that the collector passes credentials to the forum so as to appear to be a “logged in” user, e.g. simply viewing posts or browsing the forum.
A good 30% of all the OSINT sources we collect from are authenticated. To maintain continuous automated collection, we ensure that we have a sufficiently well stocked array of back up accounts for each of the forums we collect from.
Bot Protection Bypass
In some cases the sources we collect from deploy DDoS or Bot Protection. The purpose of this is typically not to prevent scraping or automated collection but more to prevent the site from high volume denial of service attacks.
The bypass for this defence varies depending on the source. In some cases, for example collection from Doxbin, we employed a CloudFlare challenge bypass method that essentially consists of:
- Detecting the browser challenge.
- Solving the challenge.
- Passing the challenge answer back and obtaining a cookie.
- Passing the cookie over to the collection processes to begin automated collection.
- Detecting when the cookie expires, ensuring any further challenge request are solved.
Even when fairly advanced bot/browser verification defences have been deployed by the target source, these have thus far all been mitigated and not prevented our automated OSINT collection.
As for the Doxbin example, the challenge of bypassing their new bot protection was significant and on balance, considering the quality of the OSINT source, might not have been warranted. It was, however, still a challenge that couldn’t be left unmatched!
CAPTCHA (Human Verification)
Automated solving of CAPTCHAs is tricky and is probably the toughest bypass we’ve had to solve so far. The amount of detailed technical information that we can share for how we go about bypassing CAPTCHA is very limited. However, it runs along similar lines to the browser challenge process, whereby detection of a CAPTCHA and the solving of it are tied into the automated collection functions.
So far there are very few OSINT sources that employ this type of challenge and we’ve been able to mitigate these in all cases whilst maintaining automated collection.

Staying Undetected
As with the above topic, it is tricky to discuss and share in any level of detail our methods for remaining “undetected“. However, in general we ensure that the accounts we use do not raise any significant cause for concern to the forum operators.
In most cases, accounts with no post count after a number of months (or sooner!) are deleted. This means that our accounts must have some level of interaction with the forum, however minimal, to ensure their persistence.
We try, wherever possible, to use Tor to access content. This helps preserve our anonymity in as much as not pinning our collectors down to one location. We also ensure we rotate things like user agents and other fingerprints to ensure relative anonymity.
Then important aspect to blending in with the noise is ensuring that collection is not overly aggressive and not overly routine. We achieve this by randomising the frequency and timings of either enumeration of new posts, fetching / viewing posts or pastes. The key is to appear sufficiently “human“. This has afforded us the ability, in some cases, to collect with the same account for a year or more without administrator intervention.
Detecting Faults
This can be even more challenging than bypassing CAPTCHA challenges. The goal for us is to ensure we have sufficiently robust detections for whenever a logged in session expires; a challenge pass expires; the very likely and common scenario of an overloaded website itself going offline or a Tor circuit is struggling.
To ensure the best chance of successfully reaching a website over Tor, we employ a number of load balanced Tor routers that are themselves proxied and balanced to cater for our crawling services and automated collection.
But things do go wrong, Tor is not the most reliable tool so our collection processes that utilise it have sufficient retry intervals and “back-off” intervals programmed into them. Should one of our requests result in a gateway time out the system will simply retry, hoping it is balanced to a less utilised Tor relay.
At times we do get detected and blocked by forum administrators. In such instances, the system will attempt to detect any “authentication loops” and select another account to continue automated collection with.
Some of the fault detection is relatively simple, such as enumerating how many pages a collection source has and iterating through each page until all pages have been collected.


The process is not always perfect, but we try to monitor it and optimise wherever possible. We spend a lot of time on the initial development phases of a collection ensuring that all possibilities, within reason, are accounted for and once a collection goes into production that any following “cat and mouse” changes required are as minimal as possible.
We hope this gives an insight into how SOS Intelligence works. We have a number of plans available and if you would like to schedule a demo, please click here.
Thanks for reading!
Amir
PS If you enjoyed this, we think you also enjoy An investigation into the LinkedIn data sale on hacker forums.
Recent Comments