Category

SOS Intelligence is currently tracking 180 distinct ransomware groups, with data collection covering 348 relays and mirrors.
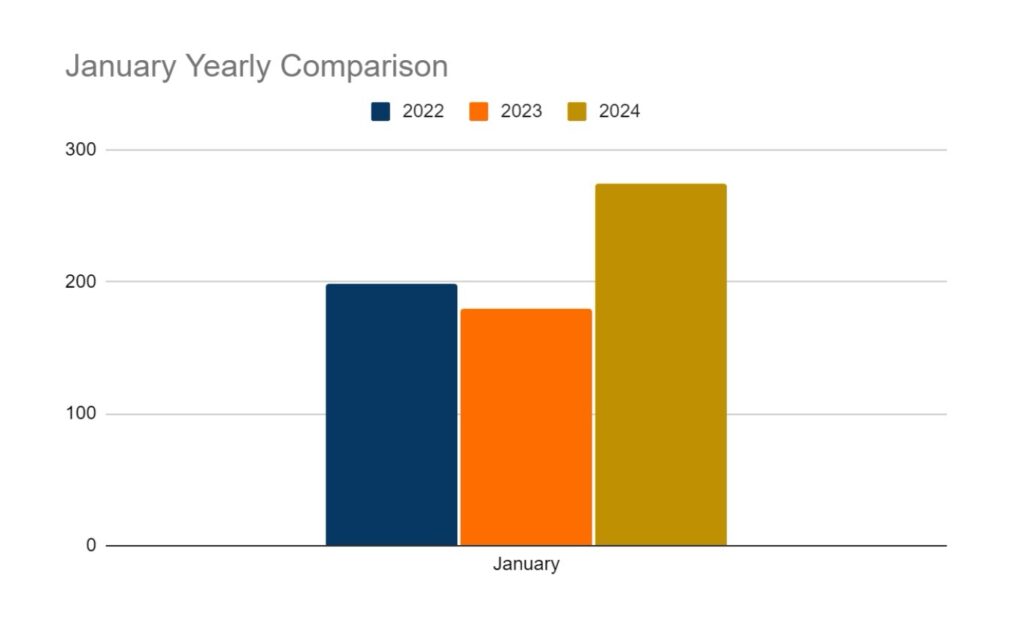
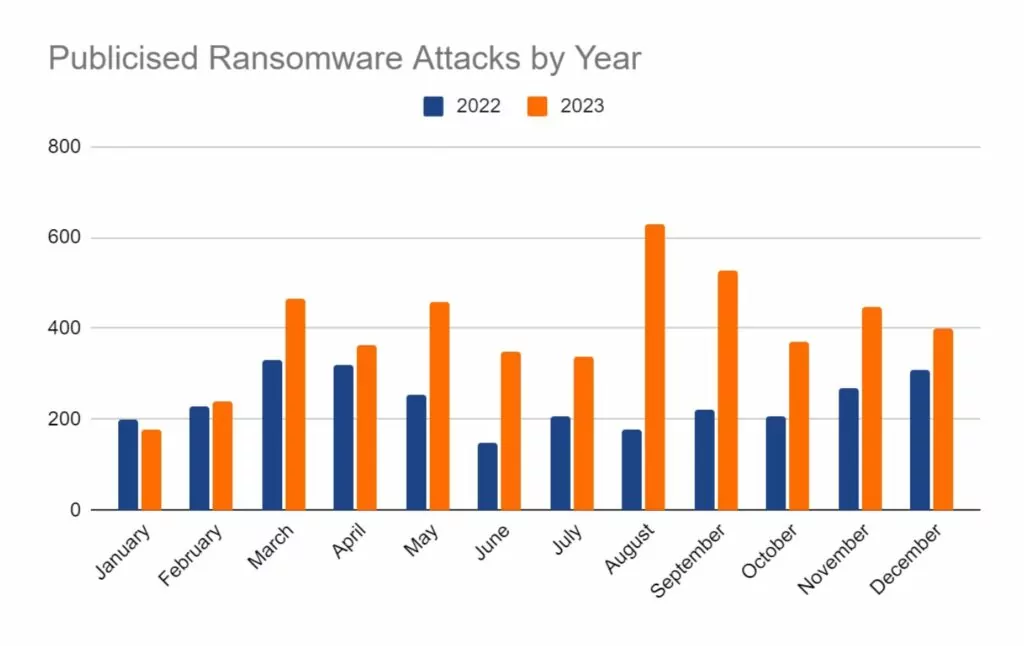
In the reporting period, SOS Intelligence has identified 395 instances of publicised ransomware attacks. These have been identified through the publication of victim details and data on ransomware blog sites accessible via Tor. Our analysis is presented below:
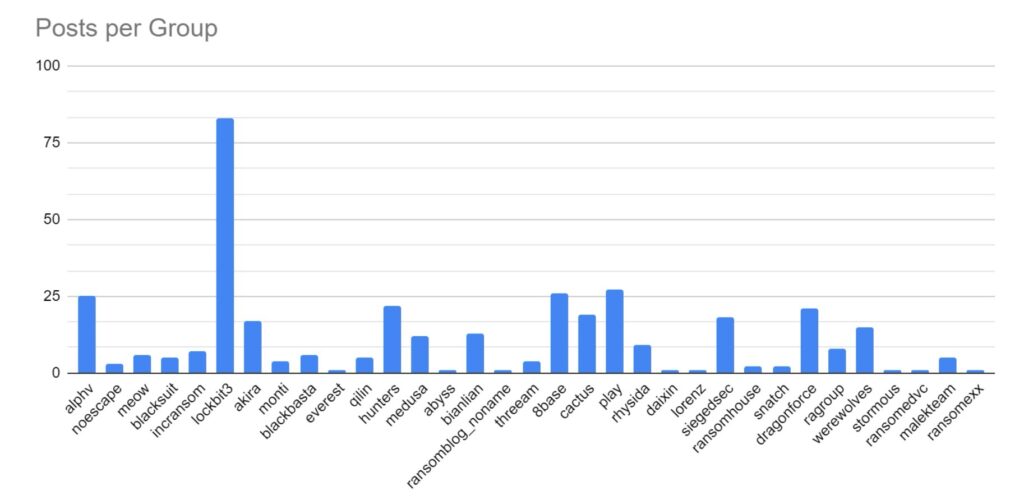
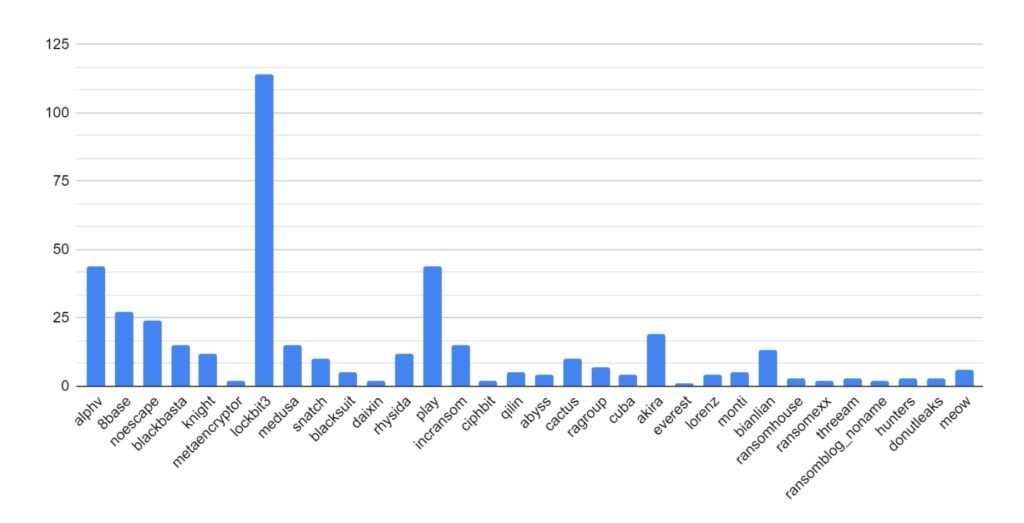
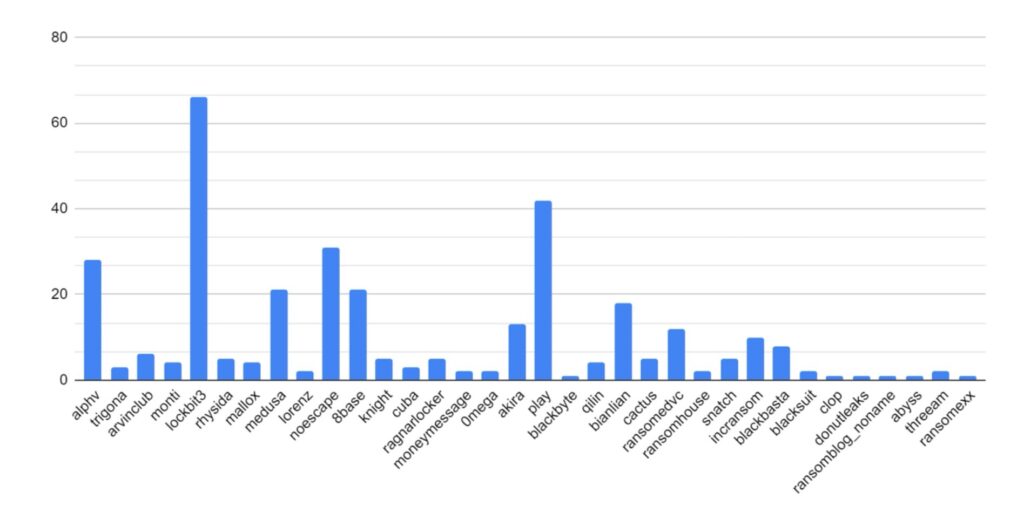
LockBit has maintained its position as the most active and popular ransomware strain.
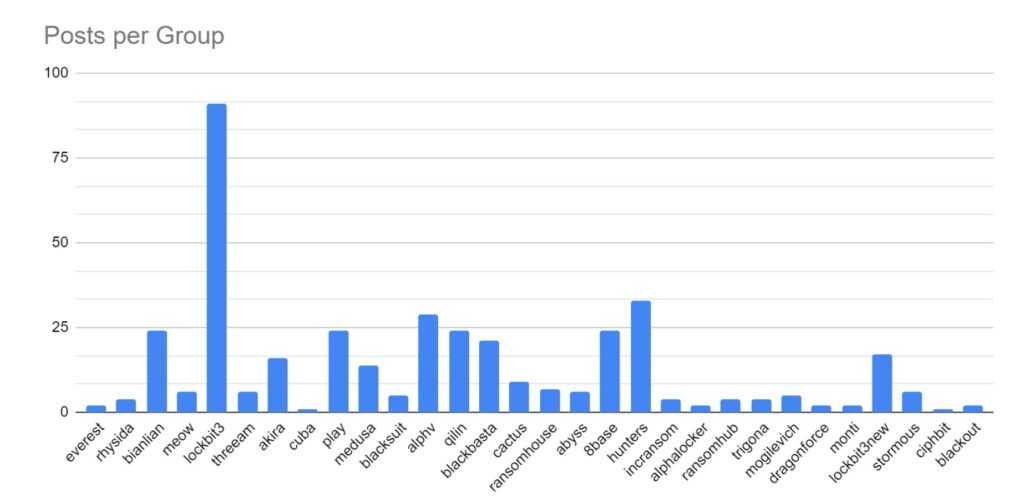
This is despite significant law enforcement interruption, the impact of which will be discussed further below.
Despite law enforcement action towards the end of 2023, ALPHV/Blackcat has maintained a strong presence online and continues to post victim data. However, owing to how the ransomware process operates, this could be seen to be victims compromised before law enforcement takedown of ALPHV/Blackcat infrastructure.
Increased activity has been identified amongst BianLian, Play, QiLin, BlackBasta, 8base and Hunters ransomware strain. This increase may be attributed to these strains absorbing affiliates from LockBit and ALPHV/Blackcat as those services went offline.
This month, Ransomhub, AlphaLocker, Mogilevich, & Blackout have emerged as new strains. Mogilevich has been observed targeting high-value victims, including Epic Games, luxury car company Infiniti, and the Irish Department of Foreign Affairs.
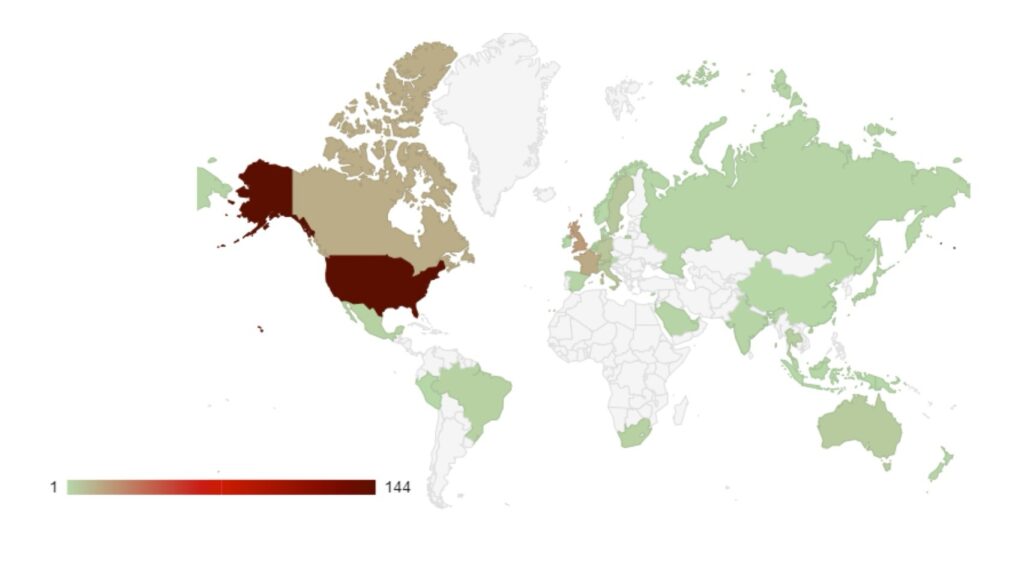
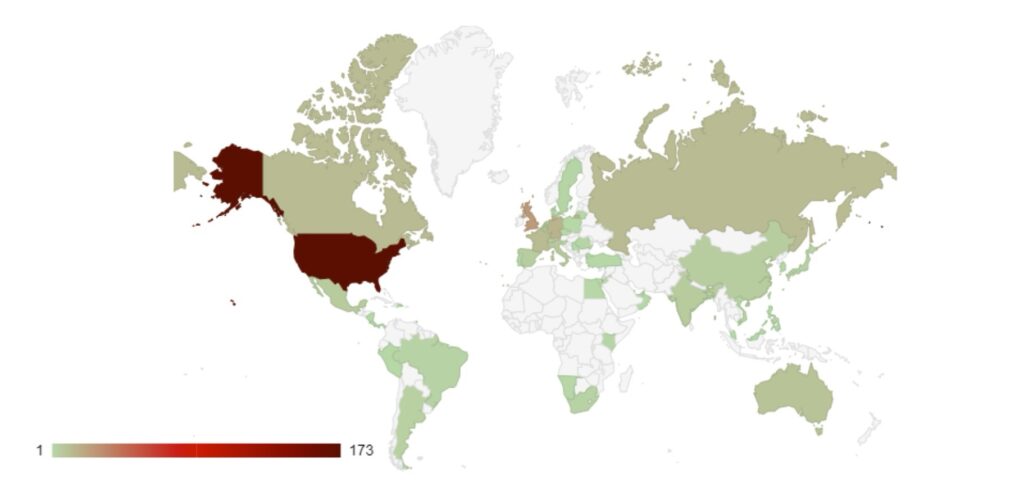
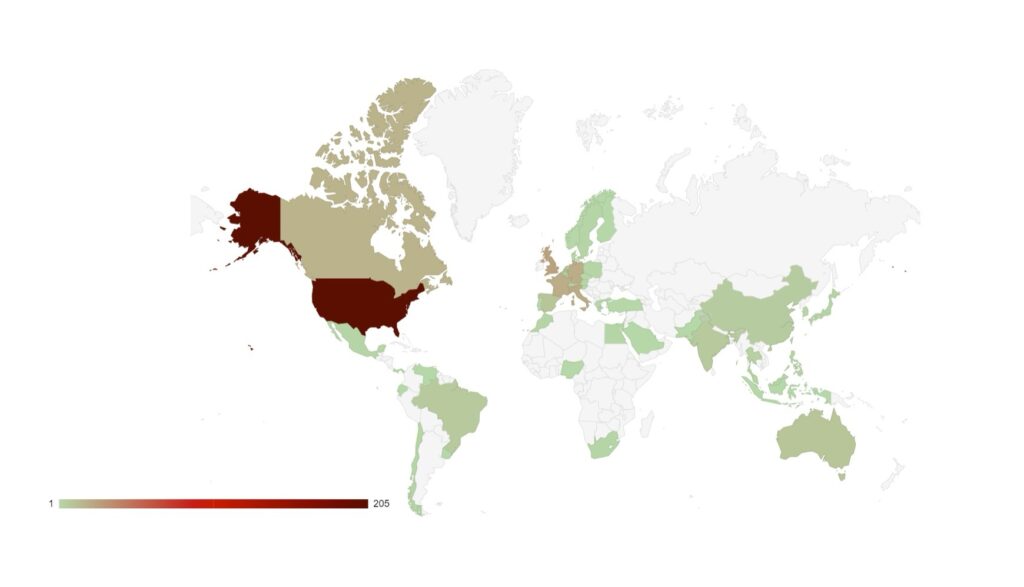
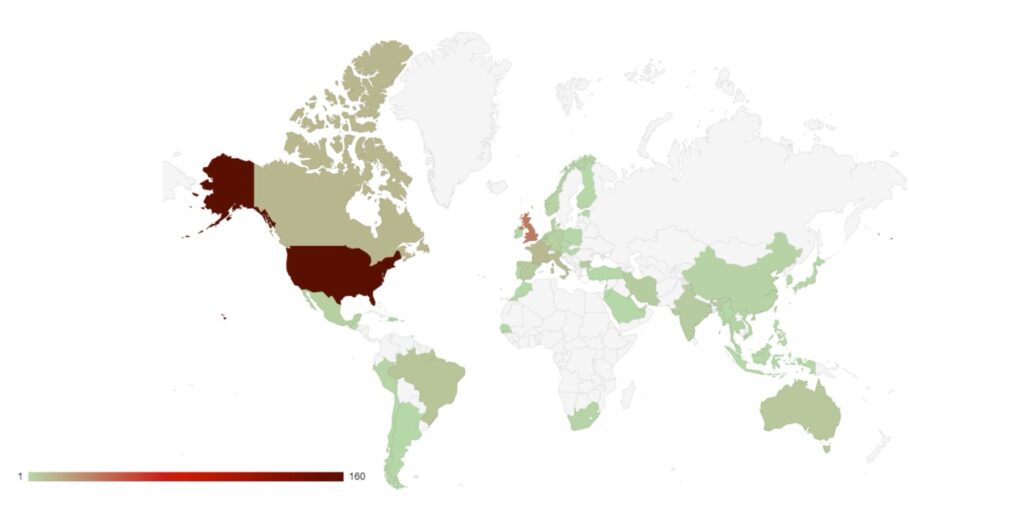
Group targeting continues to follow familiar patterns in terms of the victim’s country of origin.
Attacks have increased in South American countries, particularly in Argentina, which may be a response to presidential elections in November 2023 in which the far-right libertarian Javier Milei was elected.
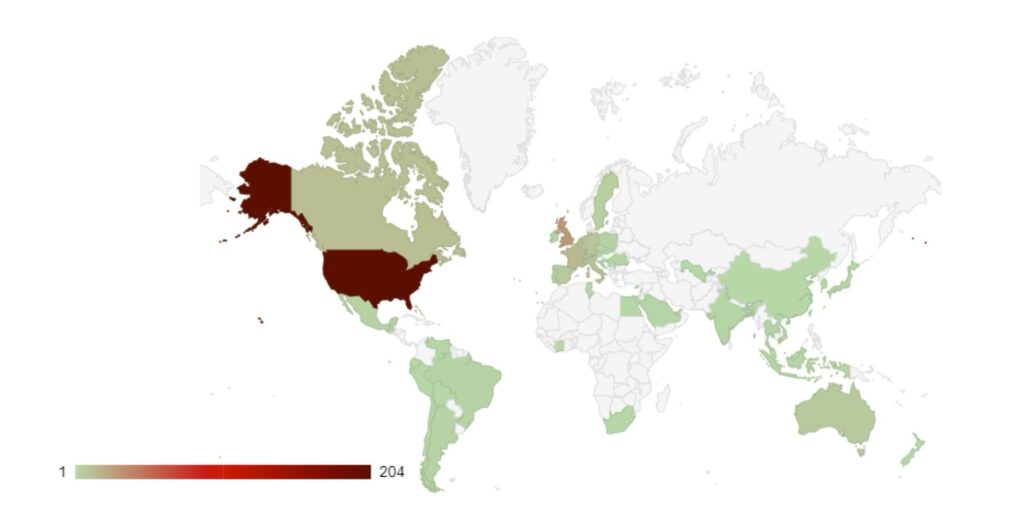
Targeting continues to follow international, geopolitical lines. Heavy targeting follows countries that have supported Ukraine against Russia. Attacks against Sweden continued as it pressed ahead with preparations to join NATO. This highlights the level of support ransomware groups continue to show towards the Russian state, and they will continue to use cyber crime to destabilise and weaken Western and pro-Ukrainian states.
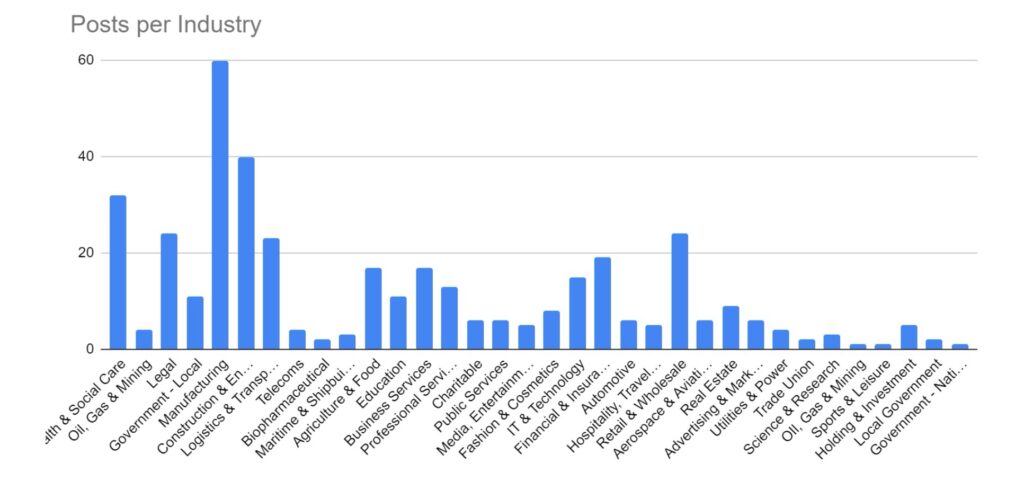
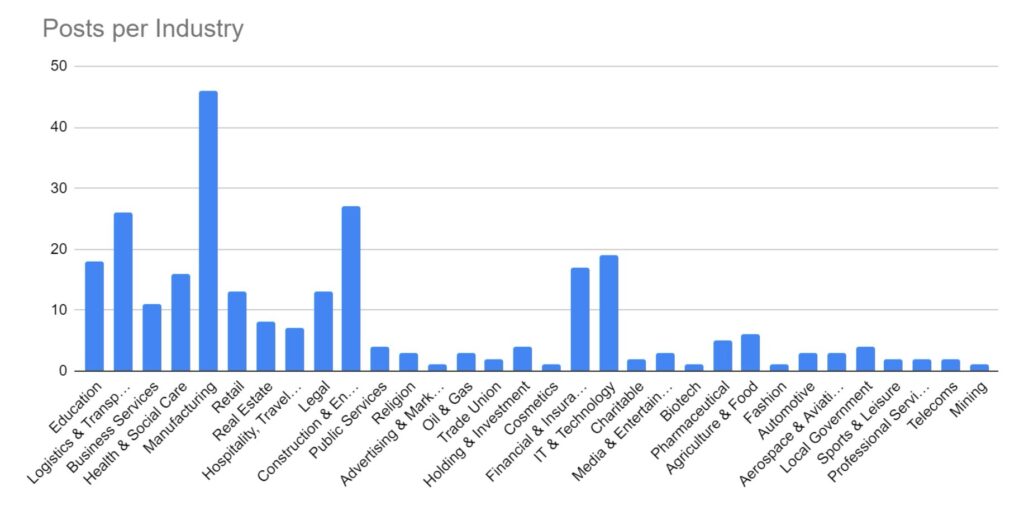
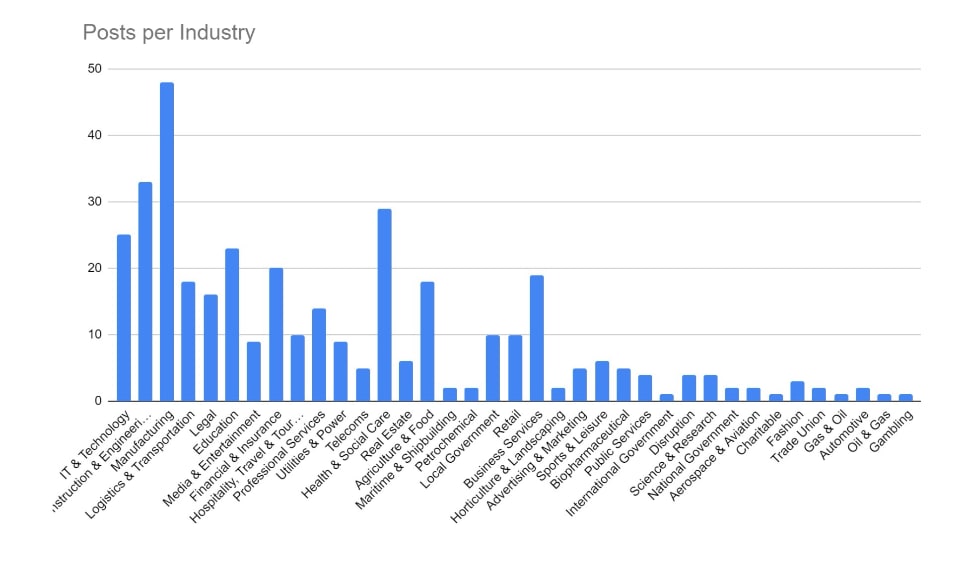
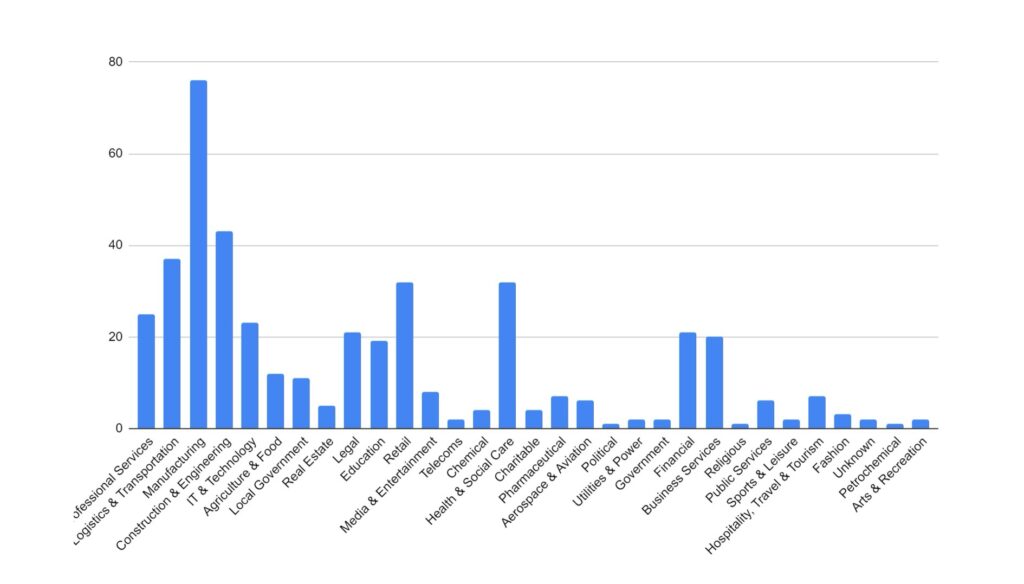
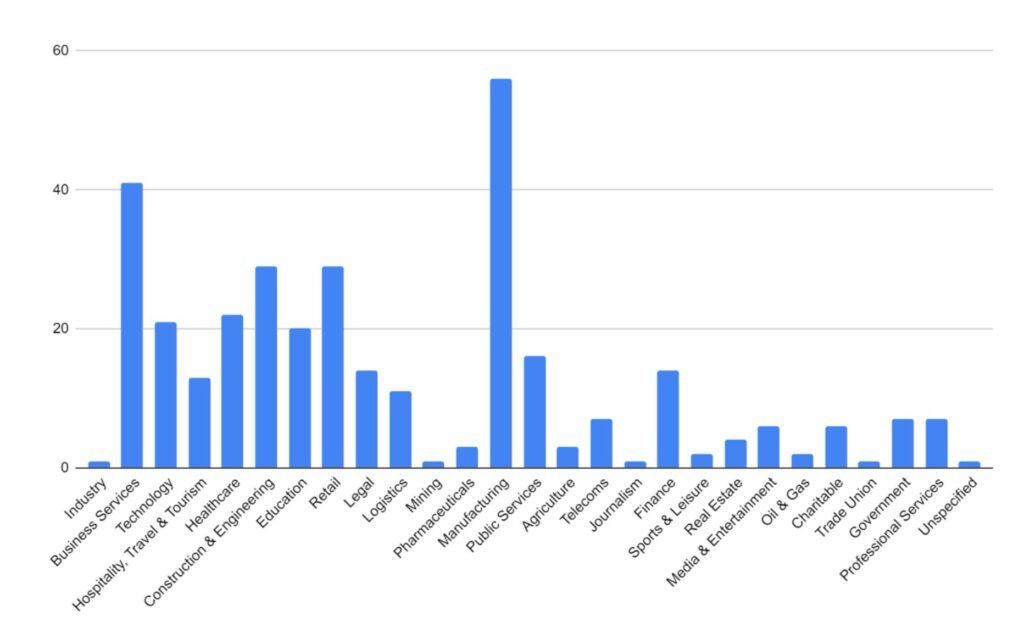
Manufacturing and Construction and Engineering have remained the key targeted industries for February. These industries would be more reliant on technology to continue their business activities, and so it logically follows that they would be more likely to pay a ransom to regain access to compromised computer systems. The Financial, Retail & Wholesale, Legal, and Education sectors have also seen increased activity over the period. Health & Social Care has seen a significant increase over the period. This is likely in response to several groups, including ALPHV/Blackcat reacting to law enforcement activity and allowing their affiliates to begin targeting these industries.
We are seeing a shift in tactics for certain industries, particularly those where data privacy carries a higher importance (such as legal or healthcare), where threat actors are not deploying encryption software and instead relying solely on data exfiltration as the main source of material for blackmail and extortion.
LockBit Takedown
On 20 February, an international law enforcement effort was successful in taking control of and shutting down the infrastructure of the LockBit ransomware strain. Much has been disclosed and said regarding the takedown, some of it speculative, however, it was confirmed by the UK’s National Crime Agency (NCA) and the US’s Federal Bureau of Investigation that control of their dark web domains and infrastructure was obtained, providing them with significant information regarding the activity of the LockBit group and its affiliates.
Since then, multiple LockBit blog sites have re-emerged, and new data continues to be published. However, it is not clear whether or not this is new activity since the takedown. It is more likely that these are victims compromised before law enforcement activity which are only now being blackmailed with data release.
We are continuing to monitor the ransomware landscape at this time to properly analyse the impact this takedown will have. This event has had a significant impact on the reputation of the LockBit group, with many affiliates angry at the perceived lack of operational security resulting in the possible identification of their real-world identities. We are anticipating many of these will look to gain access to the affiliate programs of other strains, and so we will expect to see a significant increase in reported attacks from those strains in the coming weeks and months. As for LockBit, the threat actors behind the group remain active, and it is likely we will see a re-emergence as a new group in due course.
ALPHV/Blackcat exit scam
The ALPHV/Blackcat group is making headlines for all the wrong reasons. After first having their leak site taken over by law enforcement, they now appear to have absconded with affiliate funds.
In February 2024, ALPHV/Blackcat announced an attack against healthcare provider Change Healthcare (part of United Health Group). Following this, a ransom of $22 million was paid to ALPHV. Several days later, the responsible affiliate took to the cybercrime forum RAMP to state that they hadn’t been paid their share of the spoils (potentially up to 90%). It appears now that the group has collapsed from within, ending with a final exit scam as they shut down operations. The group have further claimed to have sold their source code in the process, so we may see copycat groups emerge in due course.
While the dissolution of a notorious group should be celebrated, especially following successful law enforcement activity, it should be noted that shutting down in this way presents a significant risk to recent victims. The affiliate responsible for the Change Healthcare data, as well as affiliates who may have been similarly affected, are likely to still hold victim data and so, for those victims, there remains a risk that they may be further blackmailed as affiliates attempt to recoup their lost earnings.









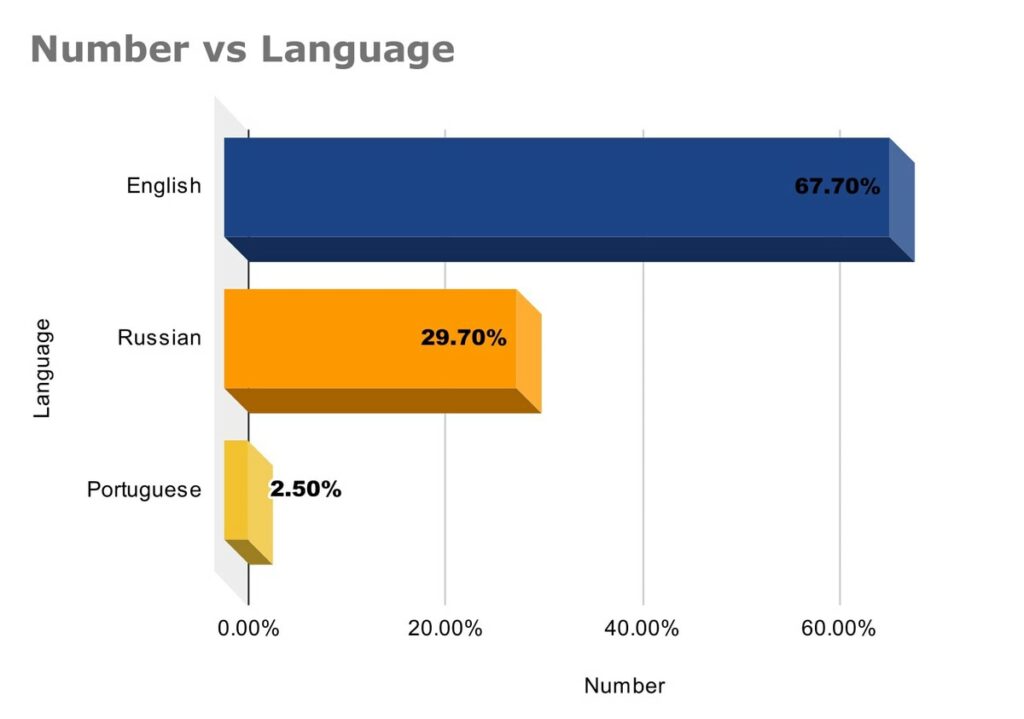
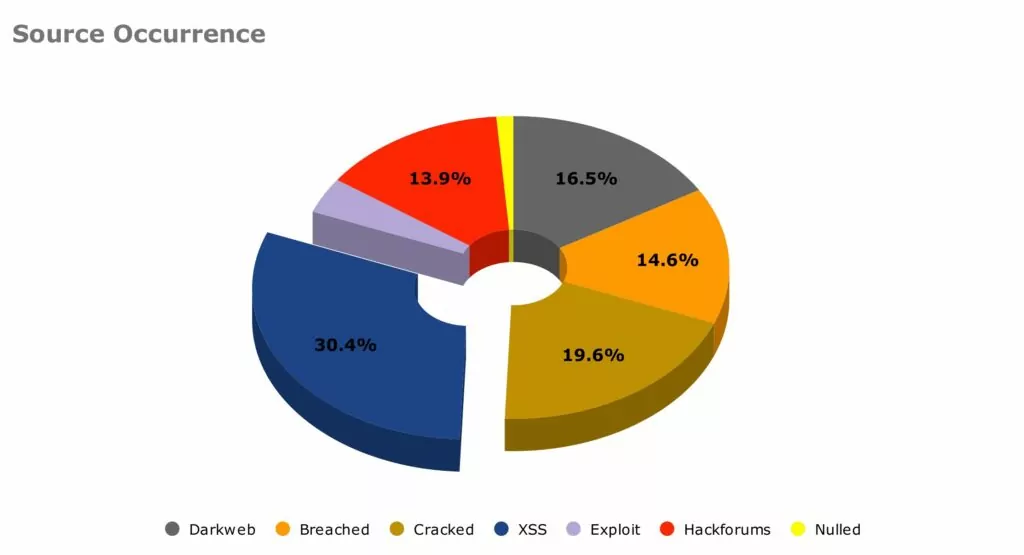
Recent Comments