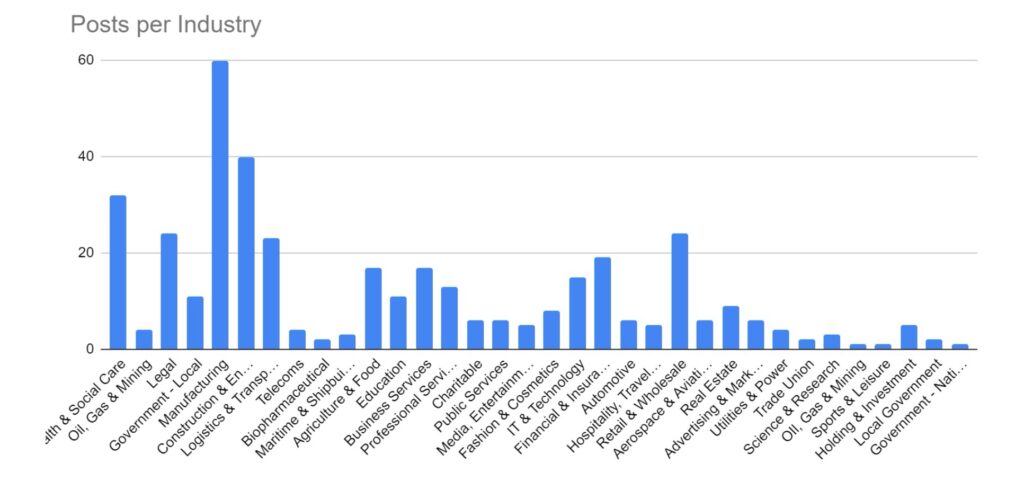
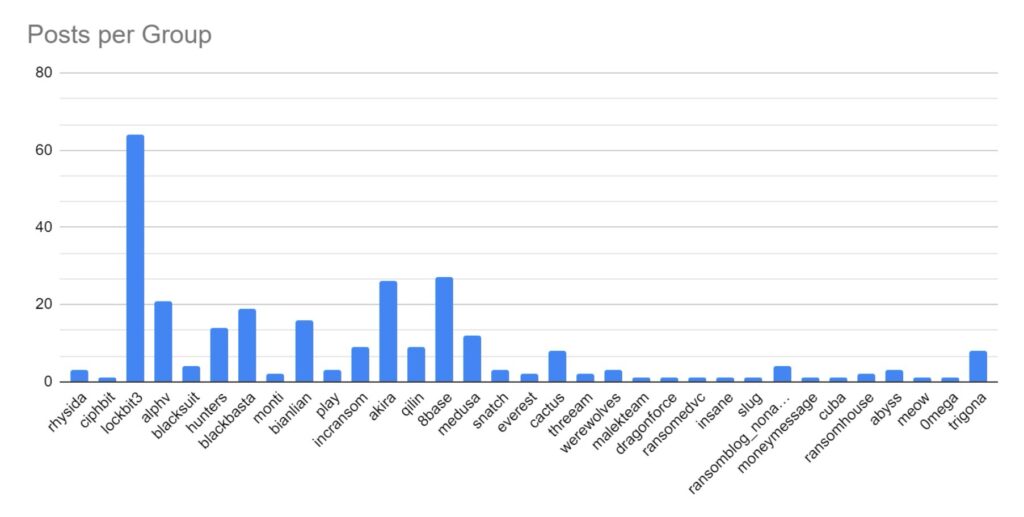
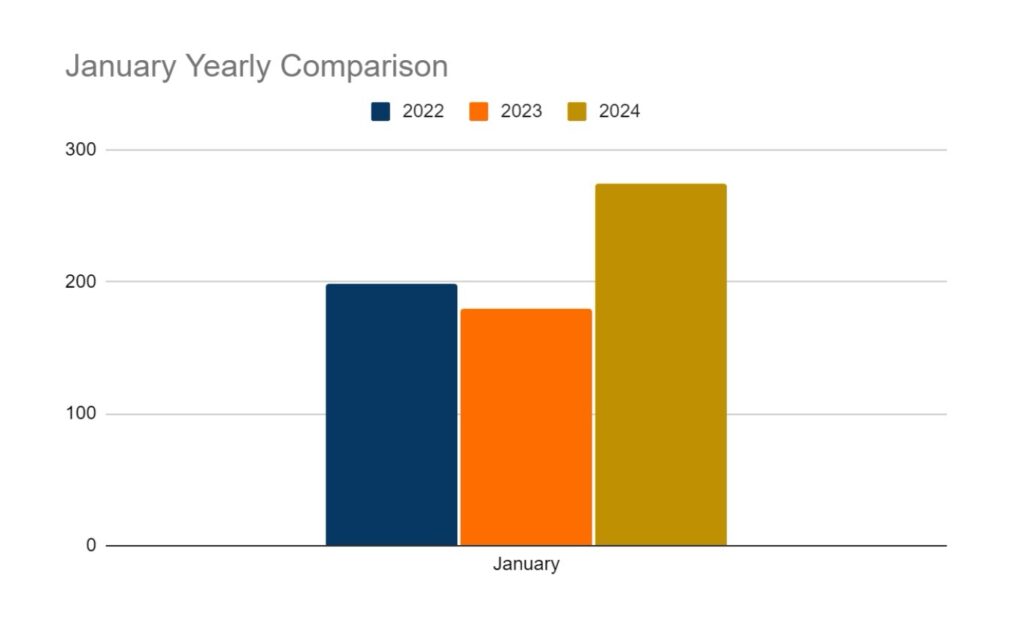
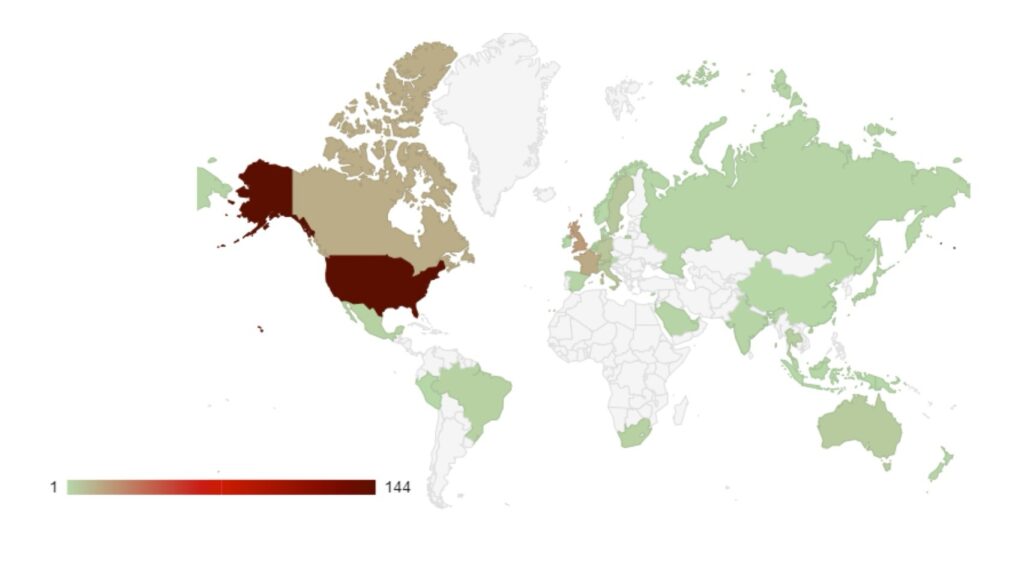
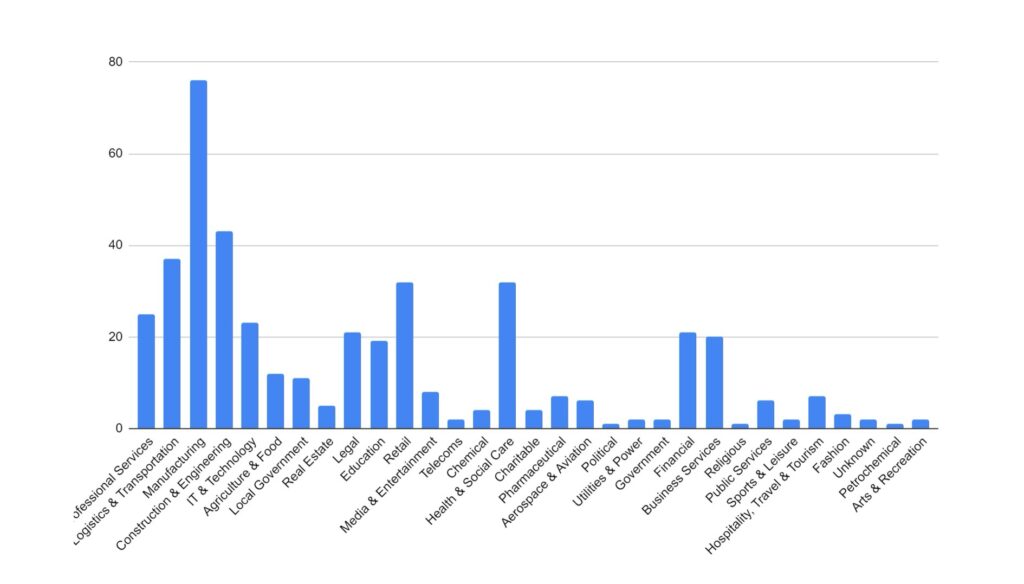
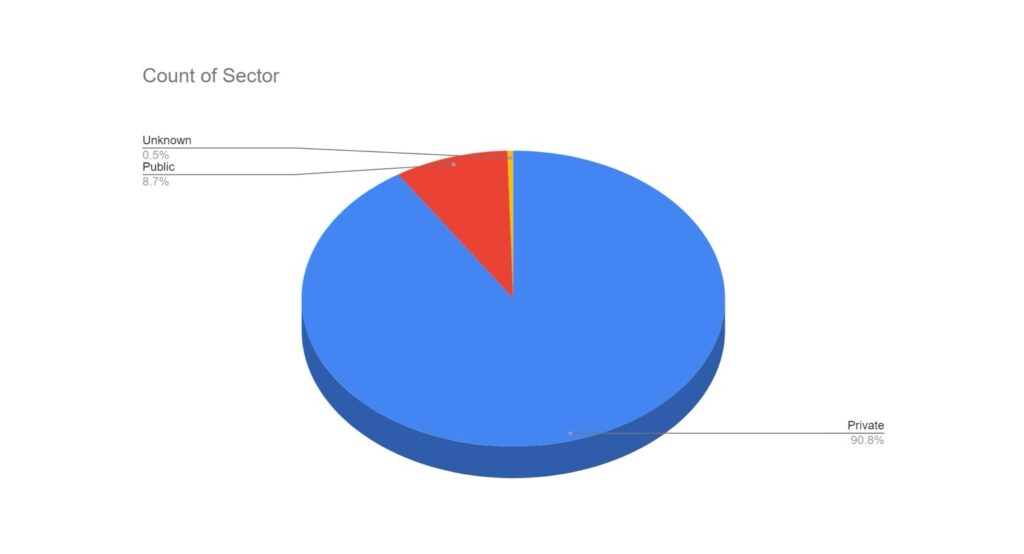
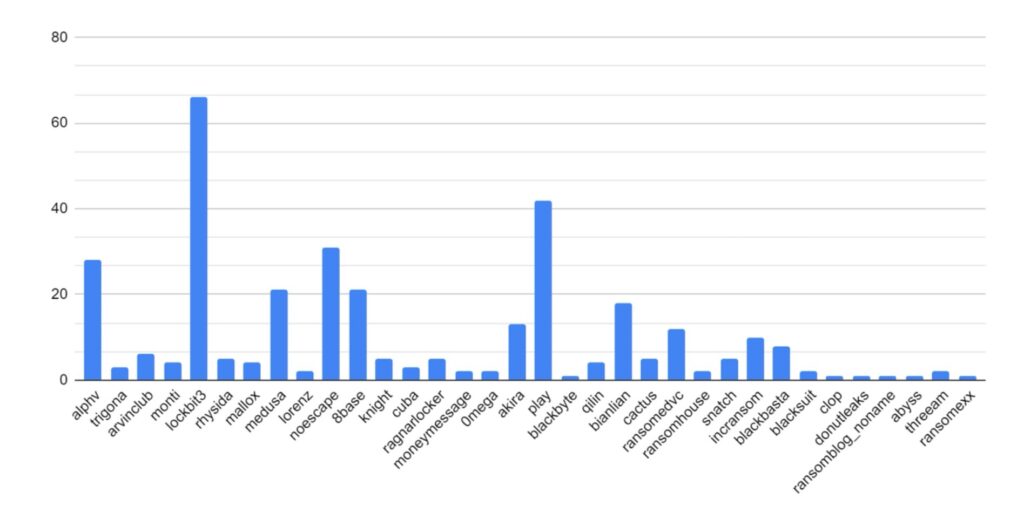
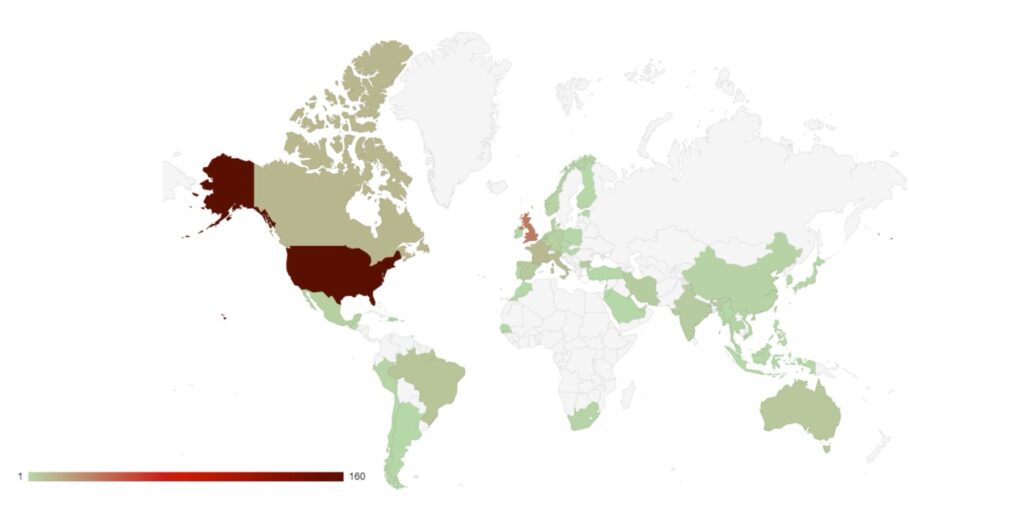
Category


Through synthetic training sample dataset generation and ML training.
Preface
Cracking CAPTCHAs is already a well-documented and established process which this article looks to expand on. We will approach this article with a general view of how we’ve cracked CAPTCHAs within undesirable conditions. This article is not meant to be a how-to or detailed guide to replicate our steps. However, it may give you some inspiration for your specific challenge.
We believe that the methods laid out in this article are novel and significantly improve the efficiency of automated CAPTCHA solving in contrast to traditional approaches. Especially when considering a target CAPTCHA system with poor sample harvesting opportunities.
Ethics
We bypass human verification checks to maintain automatic information collection pipelines. The use of the methods we have developed only extends as far as what is required to automate our collection process.
If a CAPTCHA or other human verification check system is poorly designed and not adequately rate limited, condition checked etc. bypassing it on scale may lead to a DDoS (Distributed Denial of Service) attack in the worst of cases. But with correctly implemented human verification systems, you should mitigate this even with the system bypassed. At best, unethical manipulation of these verification systems can lead to spam posts/comments and otherwise undesirable automated “bot” interaction. We do not condone this type of use.
The Problem
There are several well-established methods to automate the solving of CAPTCHAs, depending on the complexity of the CAPTCHA, and if we start at the easy end of the spectrum we are presented with a fairly basic alphabetical captcha.
With a simple distortion background, one might choose to apply a straightforward process of applying denoise filters or Gaussian blurring to an image to reduce or remove the amount of “stars” or random dot pixels present in its background that are applied at random.
This process can give us a less noisy picture and we can further convert the image to grayscale. If the source sample is a colour image doing so improves edge detection.
The image can then be processed through a standard OCR (Optical Character Recognition) library and in our experience can result in a 0.1% failure rate yielding excellent stable solutions.
In some cases, a good test of CAPTCHA ease of solvability is to feed it to Google Translate as an image; have Google Translate attempt to read the text and translate the letters back into English. If it can, then you have a very good chance that rudimentary OCR libraries will also work for you.
But this article is not about the easy end of the challenge…
What we are dealing with is a CAPTCHA that is both alphanumeric, upper and lower case with random character placement and rotation, and random disruption lines across the image and characters. Furthermore, most importantly, a point that we will discuss in more detail is where the target source is a Tor Onion website that, at the best of times loads slowly and at the worst of times is offline or responds with backend timeout errors.
The image complexity of the source CAPTCHA means it’s nearly impossible to effectively read it by OCR. This is made challenging due to the disruption patterns provided by the background random line arrangement (an outward star pattern) and each of our characters are independently disrupted with seemingly random lines of various length and width. Combining all that with offset angles of each character it’s beyond what most OCR or OpenCV methods can handle.
Therefore, for more complex CAPTCHAs image manipulation (removing noise, grey scaling etc.) is typically not sufficient. These challenges usually require machine learning to get a reasonable failure rate and sufficient solving speed.
The biggest factor in achieving a good model that will solve accurately is having a large enough sample base. In some cases, many thousands of samples are required for training. Certainly, when dealing with a CAPTCHA that may have upper, lowercase and numerical characters with randomisation of all these points plus randomisation on disruption patterns or lines the larger the sample set, the more accurate a model the training will produce.
So how do you get thousands of samples from a source that is slow to load and has poor availability, both conditions of the source being a Tor website? Harvesting samples this way would be far too inefficient and we can’t hang around!
Even with a target source that responds reasonably quickly, has good availability, and can be harvested without aggressively hitting rate limits, who would want to sit there endlessly solving eight thousand captchas to feed to an optical character recognition model?
I know that’s not going to be me! Sure, there are options to outsource these problems and crowdsource them, but those options take time, money and are likely to introduce errors in our training sample data. Neither of these is desirable, so how do we get 100% accurate sample data cheaply without human solving, without having to harvest the source, and that can scale?
The Solution
The solution we came up with was first to not focus on the solving of the CAPTCHAs, or the training of our model, or anything that was a direct result or outcome of the end goal we are driving towards. Instead, we looked at how the CAPTCHAs are constructed; what do they look like and what are their elemental parts.
We know harvesting is not an optimal option, so we have put that aside. Doing so leaves us with a handful of maybe 20 or so harvested solved CAPTCHA samples. Nowhere near enough to start training but it’s enough to start focusing on the sample set we have.
If we look at how the CAPTCHA is constructed and try and break its construction down piece by piece, in a way “reverse engineering” the construction of the CAPTCHA we might either: 1) be able to generate our own `synthetic` CAPTCHAs on demand and at scale all 100% accurately pre solved, or 2) sufficiently understand the method of construction to identify the library or process in which the CAPTCHA is constructed and reimplement it for ourselves with the same 100% accurately pre-solved outcome.
In our case and the example, we are writing this article from the path of the former option. This option was chosen as some time was spent trying to identify the particular CAPTCHA library but no exact match was found, and in the interest of not burning too much time, and depending on external factors we decided to attempt to create our own synthetic CAPTCHA generation process.
To create our CAPTCHAs, we used Pillow (a PIL Python Fork), a Python Image Manipulation Library that offers a wide range of features all well suited for the job at hand.
We start by defining a few values that we have observed to be fixed, such as a defined image size (in our case, 280 by 50 pixels) and use this to create a simple image.
Then we define our letter set (a to z, A to Z, 0 to 9) as we know these to be fixed.
Using `random.choice` we can pick a required amount of characters. In our case, the CAPTCHA uses a fixed length of 6 characters.
The text font is also important and from our source samples we see it is fixed: therefore we try to match the font type as closely as possible. Font size also remains constant. This will be important in ensuring that our training is as accurate as possible when our model is presented with real sample data.
To kick things off, the process carefully establishes the dimensions of the image canvas, akin to laying out a pristine piece of paper before beginning a drawing. Then, with a deft stroke, we construct a blank background canvas, pristine and white, awaiting the arrival of the CAPTCHA characters. But here’s where the true artistry takes centre stage; the process methodically layers complexity onto the character,
With each character in the CAPTCHA text, our process doesn’t simply slap it onto the canvas; instead, it treats each letter as an individual brushstroke, adding specific characteristics at every turn. We begin by precisely measuring the width and height of each character, ensuring that characters will not be chopped off the edges, correctly fit and fill the CAPTCHA, and that they resemble the source CAPTCHA text. Then, like with the source samples, we introduce randomness into the mix, spacing out the letters with varying degrees of separation, akin to scattering scrabble pieces.
We are also introducing a touch of chaos by randomly rotating each character, giving them a tilt that defies conventional alignment. This clever sleight of hand resembles the source samples accurately and adds to the difficulty level of solving this CAPTCHA.
Yet the process doesn’t stop there. No, it goes above and beyond, adorning our canvas with a riotous display of crisscrossing lines, as if an abstract artist had gone wild with a brush. These random lines serve as a digital labyrinth, obscuring the text beneath a veil of confusion and intrigue.
We then add and overlay lines of random length and weight across each character, aligned to the character’s angle closely matching that of the source sample.
Now that we have a way to populate our image canvas, we have a working framework with which we can iterate to get an output that resembles the source samples as closely as possible.
For now, we generate a few hundred samples, each image file is named the randomly selected CAPTCHA text, assisting us by essentially generating a sample set that has already been solved.
After that, we compared each iteration’s output closely to the source and made tweaks and adaptations. For each iteration of the CAPTCHA generator we looked closely at just one specific attribute to simplify the synthesis process. We adjust the random scattered background lines, adjusting their length, width and count. Moving then onto tweaking the letter placement and random angles, to closely match the apparent pseudo randomness of the sample data set.
Following sufficient tweaking and iterations, we are producing a CAPTCHA that is at least visually very closely matching our source samples. It matches so closely that if mixed with real samples it’s difficult to distinguish. This is the ideal level of synthesis we are looking to achieve.

Example synthetic captcha on the left, real on the right
Next steps
Now that we have a way to produce synthetic CAPTCHAs that very closely match our target, it’s time to produce a few thousand of them. This is easily and quickly done by specifying the total count in our process loop and out pops 5,000 freshly generated pre-solved captchas all nicely labelled and ready for shoving into our training process.
For model training, we’ve chosen to use the TensorFlow framework alongside the ONNX Runtime machine learning model accelerator. This combination worked well for us for both training accuracy and efficiency. All training was conducted with the use of a Nvidia GPU.
Following initial training, using just our best-produced synthetic CAPTCHA samples as our data set, we achieved a CER (Character error rate) of 3.26%. For a first batch run of a model trained against a synthetic data set was not too bad at all. But we knew we could do better.

Now that we had a model to work with, we could use it to start solving actual real target CAPTCHAs. This would allow us to generate a larger pool of real CAPTCHA samples, with a solve set, and mix those in with our synthetic set. We were looking to generate 5k synthetic and 1k real harvested CAPTCHAs with our newly trained, albeit unoptimized model.
With a framework in place that would interface with the target website, collect CAPTCHAs, generate a text prediction, check that with the website and if solved, store the solved and labelled CAPTCHA image we generated about 1,000 samples over a short time.
Feeding this back into the mix of training model data we dropped the CER down to 2.77%.

We were confident that even with 2.7% it was a rate better than a human could achieve, and we were also confident that our methodology was working.
Our remaining tasks were to reiterate the model once more, using this slightly more optimised model and generate a slightly larger set of labelled real CAPTCHAs.
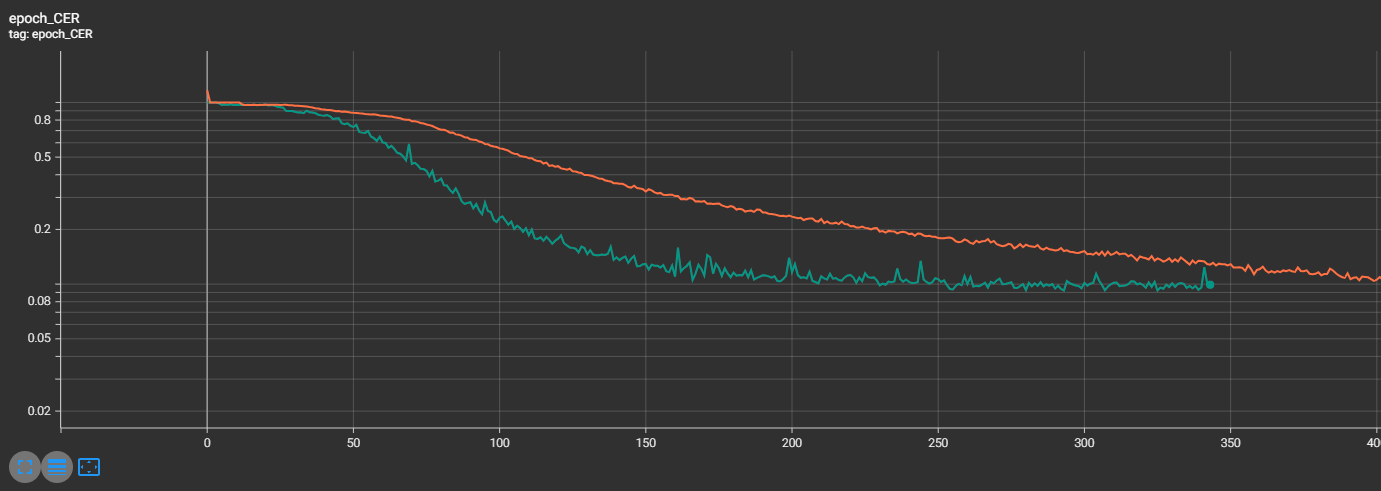
We were able to go from the initial model, with a worse CER (orange line) to the best model (green line) in only a few training iterations.
The model training improvements are best shown in the graph below with each improvement yielding a lower CER, for longer (more stable) and at a sooner point in time.
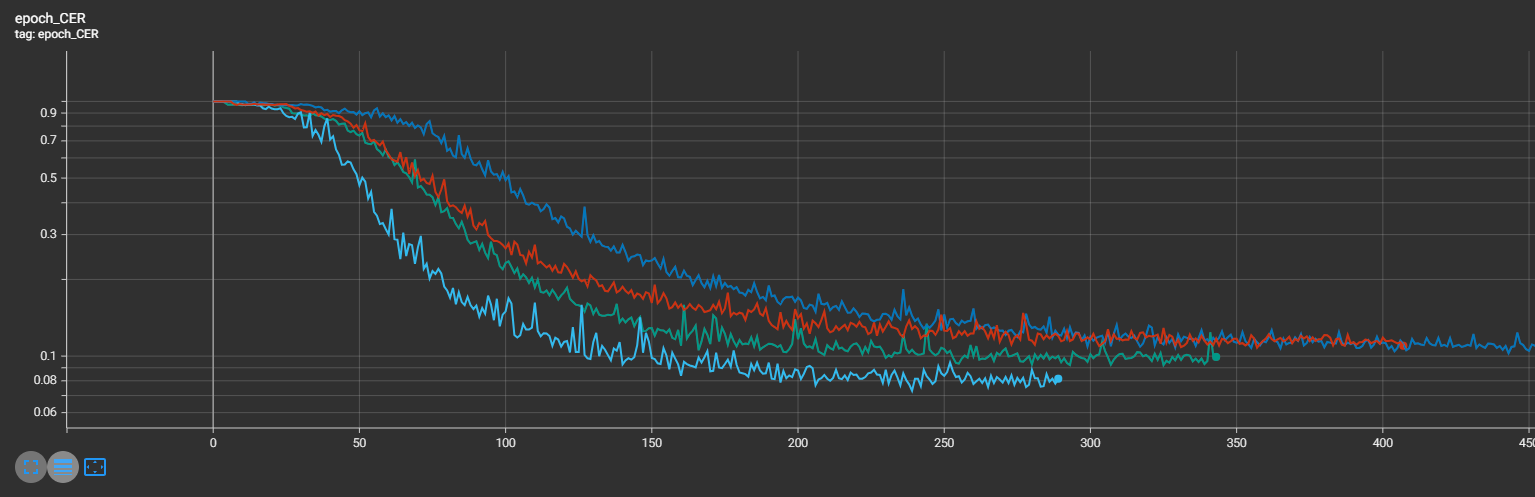
At which point we settled on a final model, with a CER of 1.4%, opting for an optimal mix real CAPTCHAs to synthetic.

Our final ML model diagram:

Once the efficacy of this model was validated it was then a task of simply plugging it into the collection pipeline process and enlivening it into our production collection system. The automated solver process has been running stable ever since and most of the disruption we’ve observed has solely been to the target source going offline and being unavailable.
Bias and Variance
A key consideration during the training process was to be aware of and mitigate where possible Overfitting and Overtraining our model. Instead of using the terms `overfitting` and `overtraining` I like to instead use Bias and Variance as two potential pitfalls of ML training as they better explain undesirable conditions that may occur. Without diving into too many details around these ML concepts as to fully understand them you would probably need a PhD. The best way I can describe what my simple mind can understand is as follows.
Due to the nature of our novel, one might say clever iterative process to train a CAPTCHA solver on a very low original source data set we are by virtue potentially adding bias into our training process. For example, from the first model any solved data sets will be solved by a model that has a predefined bias to solving a particular set, style or character combination potentially resulting in a new data set that is biassed towards what that previous model was good at solving thereby amplifying the bias in our next model’s training.
This bias would result in a real world regression of CER as the model is unoptimised to solve a wider range of character combinations and randomisation characteristics.
Our second pitfall: overfitting slides at both ends of the extreme in terms of providing an overly varied training set or an insufficiently varied training set, i.e. creeping into bias. Whereby we must consider that although we could train a model to solve many different types of CAPTCHAs, beyond just this one example, from one model using a very varied data set doing so and if not carefully tuned could result in `overfitting` our data set thereby introducing an unoptimised CER as our model is essentially training on more noise than signal.
We therefore considered both Bias and Variance closely, ensuring a healthy mix of varied real correctly labelled CAPTCHAs harvested from source to a ratio of synthetically generated CAPTCHAs with a randomly distributed character set. An optimal CER band was then discovered through iterative AB testing of data set mix, training iterations until a stable plateau was identified.
Conclusion
We deploy a final model, incorporating a mix of synthetic and real CAPTCHAs, achieving a CER of 1.4%. The automated solver process seamlessly integrates into our production collection system, ensuring stability and efficiency.
By leveraging synthetic sample training data generation, we’ve advanced CAPTCHA cracking. Our approach offers an effective and efficient solution for CAPTCHA cracking without significant human involvement or effort allowing for effective automated data collection.
With this capability, we are able to add value to our customers by automating the collection from otherwise programmatically inaccessible sources, where we would have to manually have a human solve the CAPTCHA access the page, insert any updates and then alert our customers. Automation is key to what we do at speed and at scale especially when dealing with many hundreds of collection sources as we do.
Photo by Kaffeebart on Unsplash.







Recent Comments